Die Wayback Machine (wörtlich, auf Deutsch übersetzt: Weg-Zurück-Maschine) ist ein Weg für eine Reise in die Vergangenheit, zumindest beim Betrachten von Webseiten. Die Wayback Machine greift hierbei auf die Datenbank vom Internet Archive zu. Das Internet Archive ist die größte Bibliothek der Welt für Webseiten. In regelmäßigen Zeitintervallen werden hier Milliarden an Webseiten besucht und dokumentiert.
Inzwischen umfasst die Sammlung dieser Momentaufnahmen bereits über 525 Milliarden Einträge. Täglich kommen neue Inhalte hinzu. Im Monat sind es schätzungsweise 20 Terabyte, die gesamte Datensammlung liegt inzwischen im Petabyte-Bereich.
Zum einen ist das schön, um sich den historischen Verlauf bestimmter Seiten anzusehen, zum anderen kann das Tool überaus nützlich sein. Beispielsweise um festzustellen, welche Seite einen Inhalt zuerst hatte oder um bei der Rekonstruktion einer WebseiteEine Webseite ist eine Seite im World Wide Web. Diese kann aus einer Einzelseite (Onepager) oder mehreren Unterseiten bestehen. Als Synonym kennt man auch die Begriffe Internetseite, Webpage, Website, Webpräsenz, Webauftritt, Internetpräsenz, Homepage oder einfach nur Seite. Eine Webseite liegt in an die ehemaligen Inhalte zu gelangen.
Besonders gut ist, dass es sich nicht einfach nur um einen Screenshot handelt, sondern um die gesamte HTML-Version, sodass nicht nur der Aufbau analysiert werden kann, sondern auch Links anklickbar sind. Aber beachte, dass du nicht auf den aktuellen LinkEin Link ist eine Verknüpfung zu einer anderen Webseite oder zu einem anderen Ort im Internet. Ein Link kann in Text oder auf einem Bild auf einer Webseite verwendet werden, um eine Verbindung zu einer anderen Webseite herzustellen. Mehr springst, sondern auf den historischen in der Wayback Machine.
Wayback Machine Screenshot 2021
Die Geschichte der Wayback Machine
Im Jahr 1996 wurde dieses geniale und gemeinnützige Projekt von Brewster Kahle ins Leben gerufen. Das damalige Ziel war es, barrierefrei digitale Inhalte in einem Langzeitarchiv zu dokumentieren. Zu diesem enorm großen Archiv gelangst du durch die Wayback Machine.
Dieses lange Gedächtnis vergisst nichts und zeigt eindrucksvoll die Entwicklung der Webseiten mit Inhalt und Design. Eine echte Zeitreise im wahrsten Sinne des Wortes. Übrigens ist in den USA im Bundesstaat Kalifornien diese Institution eine anerkannte Bibliothek.
Aber dieses ehrgeizige Projekt, welches enorme Serverressourcen verbraucht, speichert nicht nur Webseiten, sondern zusätzlich Videos, Software, Musik, Audiodateien, Bücher und vieles mehr.
Ist meine Webseite in der Wayback Machine enthalten?
Das kannst du ganz einfach prüfen! Gehe auf die Seite archive.org/web/ und gib im Suchfeld deine DomainEine Domain ist im Grunde der Name eines Teilbereichs im Internet, also zum Beispiel einer Webseite. Es ist ein alphanumerischer Code, also eine Zusammensetzung von Buchstaben, der möglichst logisch ist, um die Findung für den Menschen leichter zu machen. Über den Namen, also die Domain, lassen s ein. Es dauert gar nicht lange, dann siehst du die Ergebnisse. Wenn deine Seite noch sehr neu oder unbekannt ist, dann es unter Umständen sein, dass sie nicht aufgeführt ist. Das kannst du aber ganz einfach und kostenfrei ändern. Gehe rechts unten auf „Save Page Now“ und gib die URLDie Abkürzung URL steht für "Uniform Resource Locator" und wird in der Regel als Webadresse oder Internetadresse bezeichnet. Durch Eingabe der URL kannst du auf Inhalte im Internet zugreifen. Durch diese Adresse ist dein Computer in der Lage, mit dem Server einer Webseite zu kommunizieren. Dieser deiner Webseite ein:
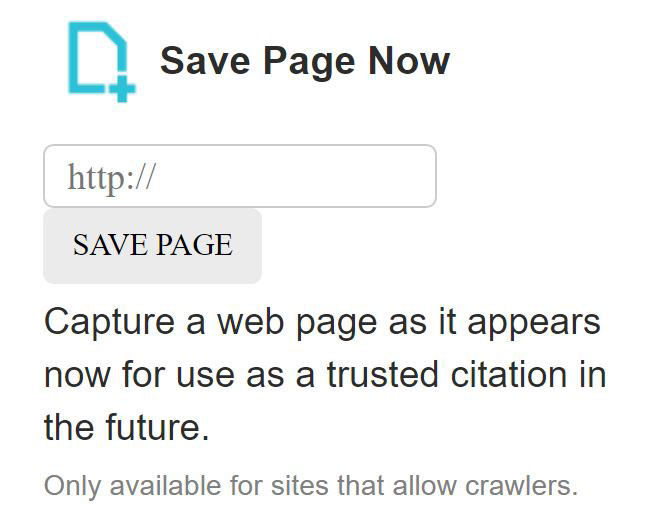
Schon wird deine Seite ins Archiv mit aufgenommen.
Wenn die gesuchte Webseite bereits aufgeführt ist, dann gelangst du ins Archiv. Hier siehst du als tabellarischen Kalender und als Balkendiagramm mit Zeitstrahl alle Einträge seit 1996:
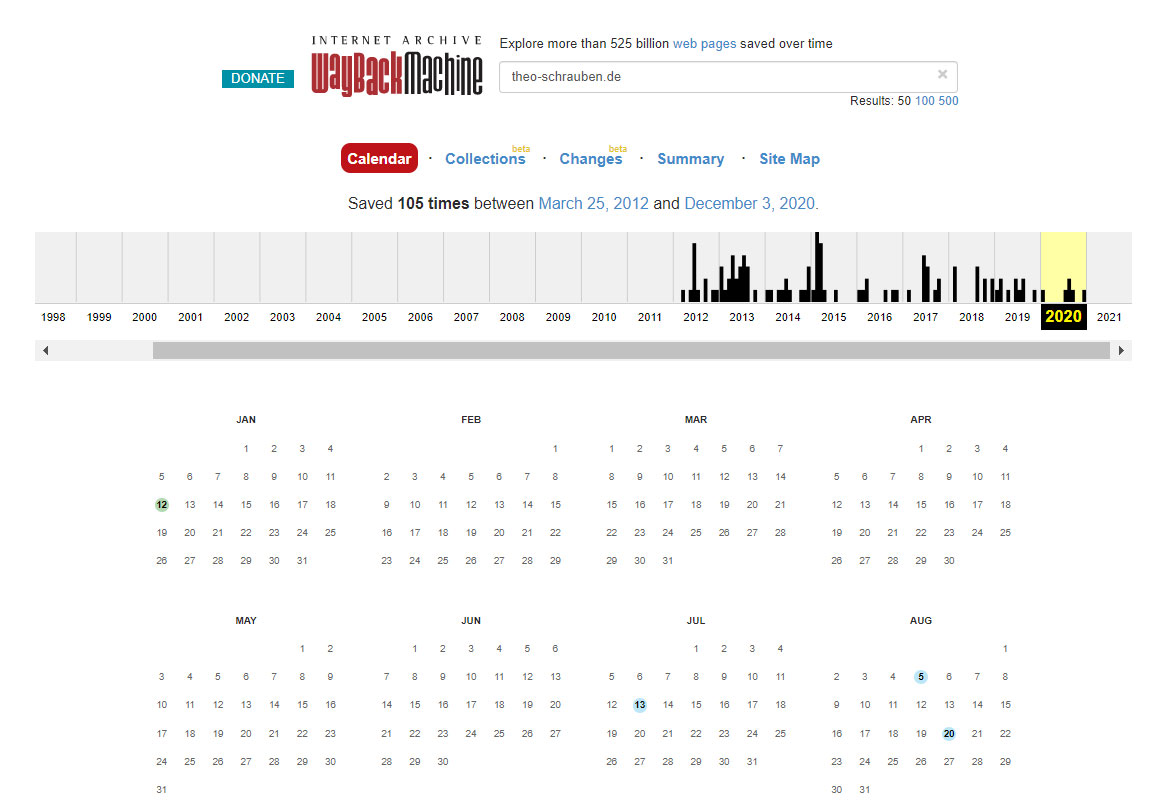
Nun kannst du entweder noch das gewünschte Jahr oben im Zeitstrahl anklicken oder gleich zum gewünschten Eintrag springen. Alle blau markierten Daten bieten einen Eintrag, den du dir anzeigen lassen kannst. Wenn du das Datum klickst, dann siehst du, wie die Webseite zu diesem Zeitpunkt ausgesehen hat.
Tipp: Übrigens kann man nicht nur Webseiten suchen, sondern auch SuchbegriffeIm Marketing ist das Wort Suchbegriff gleichzusetzen mit Keyword. Hierbei handelt es sich um eine Wort oder eine Wortkombination, welche Nutzer in der Suche der Suchmaschinen eingeben, um bestimmte Inhalte zu finden. Die Suchmaschine versucht daraufhin ein passendes Suchergebnis zu präsentieren, we Mehr. Dann bekommst du relevante Webseiten zum KeywordIm Onlinemarketing ist ein Keyword ein Schlüsselwort, welches aus einem oder mehreren Wörtern bestehen kann. Dieses Keyword ist gleichermaßen ein Suchbegriff, welcher in der Suchmaschine gesucht wird und optimiert werden soll. Hierbei gibt es unterschiedliche Formen von Keywords:
• Shortta Mehr angezeigt. Klicke einfach auf eine der angezeigten Websites und wähle das gewünschte Datum.
Wenn du deine Webseite nicht in der Wayback Machine indexiert sehen möchtest, dann kannst du den CrawlerEin Crawler ist ein automatisiertes Computerprogramm, welches Webseiten und deren Informationen durchsucht. Suchmaschinen-Anbieter verwenden Crawler um aus den Informationen von Milliarden an Webseiten einen Index aufzubauen. Aus diesem Index werden dann die Suchergebnisse gespeist. Mehr Information Mehr vom Internet Archive aussperren und damit das Sammeln der Daten verbieten. Hieran hält sich der Crawler. Folgender Code kommt in die robots.txtHinter dem Begriff Robots.text versteckt sich eine Datei. Diese Datei speichert man im Hauptverzeichnis der Domain. Hier findet der Crawler der Suchmaschine deine Robots.txt Datei und kann sie auslesen. Er erfährt so, welche Verzeichnisse und Dateien er crawlen soll und welche ggf. gesperrt sind. D Mehr:
User-agent: ia_archiver
Disallow: /
Bedenke, dass die Verbannung erst für die Zukunft gilt. Aber es besteht auch die Möglichkeit, die Einträge der Vergangenheit als Besitzer löschen zu lassen. Nur weil der Inhalt aus der Maschine entfernt wurde, bedeutet das nicht, dass er aus dem Internet verschwunden ist. In irgendeiner dunklen Spalte kann immer noch eine Kopie lauern. Denn es gibt natürlich auch Bots, welche die Inhalte der Wayback Machine sammeln und speichern.
Probleme beim Abruf
Auch wenn das Projekt an sich ein echtes Goldstück ist, hat man von Zeit zu Zeit das ein oder andere Problem. Teilweise sind nicht alle Daten und Seiten in der Maschine zu sehen. Gerade wenn man die weiteren Funktionen nutzt und unter Summary sich die Statistiken zu den indexierten Dateien wie Text, HTMLHTML (HyperText Markup Language) ist eine Programmier- bzw. Formatierungssprache, mit der Webseiten erstellt werden. Es ist eine Auszeichnungssprache, die dazu verwendet wird, mithilfe von diversen HTML-Tags den Inhalt einer Webseite zu strukturieren und zu formatieren. HTML ist die Grundlage fast a Mehr, Bilder, Videos etc. ansieht, muss man mitunter lange warten und bekommt am Ende kein vollständiges Ergebnis. Das kann mitunter auch an JavaScriptJavaScript (JS) ist eine Programmiersprache, welche es ermöglicht, Webseiten dynamisch zu machen. Die Skriptsprache wurde 1995 entwickelt, um die Möglichkeiten von HTML und CSS zu erweitern. Dafür wird sie auch heute noch genutzt, doch kann sie inzwischen viel mehr. Während sie anfangs lediglich liegen oder der Größe der Datei. Übrigens kann man auch eine Sitemap aller URLs abrufen.
Browser Erweiterungen
Für die Tech-Affinen gibt es ein geniales Plug-in bei Google Chrome. Hiermit kann man beim Surfen sich die Historie der Webseite ansehen. Zugegeben kommt das in der Praxis nicht so oft zum Tragen, aber es kann sehr praktisch sein, wenn man auf eine 404-Fehlerseite trifft. Neben dieser Funktion kann das Plug-in Folgendes:
- aktuelle Seite im Archiv speichern
- kürzliche Version anzeigen
- erste gespeicherte Version anzeigen
- Überblick geben
- Alexa-Daten abrufen
- eine Whois-Abfrage machen
Nutzen in der Praxis
Wayback Machine und Webdesign
Ich persönlich nutze die Wayback Machine gerne, wenn ich eine Webseite für Kunden gestalte, um mir den Verlauf seines Designs anzusehen. Dadurch bekomme ich ein gutes Gefühl für seine Entwicklung und mitunter entdecke ich auch Inhalte, die wieder ausgegraben werden. Beispielsweise konnte ich bei der Webseite eines Fotografen wunderschöne Bilder aus der Vergangenheit finden. Dieser wusste gar nicht mehr, dass es diese Aufnahme gibt und war vom Re-Design sichtlich begeistert.
SEO mit der Wayback Machine
Aber auch bei der Suchmaschinenoptimierung ist sie ein gängiges Tool. Hierfür habe ich mehrere Einsatzszenarien. Es kommen des Öfteren Kunden zu mir, die durch einen Webseitenumzug und fehlende Weiterleitungen ihre RankingsDas Ranking beschreibt eine Rangfolge oder einen Rang in der SEO bezogen auf die Position in den Suchergebnissen. Das beste Ranking ist demnach die erste unbezahlte Position. Die Position ist abhängig von vielen Faktoren. Wenn man anhand der Rankings zu den unterschiedlichen Keywords und deren Such Mehr verloren haben. Über die Wayback Machine kann ich diese Inhalte rekonstruieren.
Aber auch die Struktur der vorherigen Seite kann dadurch analysiert werden. Mitunter ist ein Relaunch einer Webseite nicht immer ein Erfolg in der Webseite. Es sind oft kleine einfache Details, die den Kunden Rankings kosten. Hier ist ein Blick in die Vergangenheit ein wahrer Segen.
Ich kenne SEO-Kollegen, die sich auf den Domainkauf und die Rekonstruktion seiner Inhalte spezialisiert haben. Sie halten Ausschau nach Domains, die aufgegeben werden und zu ihrer Zeit eine starke Sichtbarkeit hatten. Diese werden dann gekauft und die Inhalte werden wieder zum Leben erweckt, in der Hoffnung, dass Google der Domain ihre alte Autorität zurückgibt.
Rechtliches zur Wayback Machine
Aber auch rechtlich kann die Zeitmaschine eine Hilfe sein. Wie weist man besser nach, dass man der Urheber eines Inhalts ist, als der Beweis durch ein unabhängiges Medium? Hier kann die Maschine zeigen, wer als Erstes einen Inhalt veröffentlicht hat. Die Snapshots aus der Wayback Machine wurden in der Vergangenheit bereits bei Gerichtsverfahren als Beweis zugelassen. Auch wenn man Duplicate ContentDuplicate Content ist englisch für doppelter Inhalt. Darunter versteht man identische Inhalte, die sich auf mehreren Webseiten oder Unterseiten finden. Man kann unterscheiden zwischen internem DC und externem DC. Interner DC ist, wenn auf der eigenen Webseite mehrere Seiten den gleichen Inhalt habe Mehr von Mitbewerbern auch theoretisch über die IndexierungUnter der Indexierung versteht man das Aufnehmen von Informationen in einen Index. In diesem Index können dann die Inhalte nach spezifischen Merkmalen aufbereitet werden. Beispielsweise der Zuordnung von Schlagworten. Der Index beschleunigt das Auffinden von Inhalten, ähnlich einem Bücherindex. A Mehr in der Search Console nachweisen kann.
Aber genau im rechtlichen Bereich gibt es auch Kritik an diesem Tool. Denn sie erstellt Kopien von Webseiten, ohne die Erlaubnis ihrer Besitzer einzuholen. Diese werden der Öffentlichkeit zur Verfügung gestellt. Der Urheber wird nicht gefragt, ob er damit einverstanden ist.
Fazit zur Nutzung
Egal ob für den romantischen Nostalgiker oder für den professionellen Webdesigner, die Wayback Machine ist in jedem Fall einen Besuch wert! Man kann mit diesem Werkzeug viele nützliche Erkenntnisse erlangen und sich auch Unmengen an Inspirationen holen. Dieses historische VerzeichnisEin Verzeichnis kann auch als Register, Katalog, Ordner oder Auflistung bezeichnet werden. Hier werden Informationen in einer Liste mit einer definierten Sortierung aufgeführt. Die typische Standardsortierung ist alphabetisch. Bereits im Mittelalter wurden Verzeichnisse in der Verwaltung genutzt. A ist eine Bereicherung für das Internet und verdient auch Unterstützung.
0 Kommentare